
[ad_1]
Summary
Daily on Roblox, 65.5 million customers interact with hundreds of thousands of experiences, totaling 14.0 billion hours quarterly. This interplay generates a petabyte-scale knowledge lake, which is enriched for analytics and machine studying (ML) functions. It’s resource-intensive to affix truth and dimension tables in our knowledge lake, so to optimize this and cut back knowledge shuffling, we embraced Discovered Bloom Filters [1]—sensible knowledge buildings utilizing ML. By predicting presence, these filters significantly trim be part of knowledge, enhancing effectivity and lowering prices. Alongside the best way, we additionally improved our mannequin architectures and demonstrated the substantial advantages they provide for lowering reminiscence and CPU hours for processing, in addition to growing operational stability.
Introduction
In our knowledge lake, truth tables and knowledge cubes are temporally partitioned for environment friendly entry, whereas dimension tables lack such partitions, and becoming a member of them with truth tables throughout updates is resource-intensive. The important thing house of the be part of is pushed by the temporal partition of the very fact desk being joined. The dimension entities current in that temporal partition are a small subset of these current in all the dimension dataset. In consequence, the vast majority of the shuffled dimension knowledge in these joins is ultimately discarded. To optimize this course of and cut back pointless shuffling, we thought-about utilizing Bloom Filters on distinct be part of keys however confronted filter measurement and reminiscence footprint points.
To deal with them, we explored Discovered Bloom Filters, an ML-based answer that reduces Bloom Filter measurement whereas sustaining low false constructive charges. This innovation enhances the effectivity of be part of operations by lowering computational prices and enhancing system stability. The next schematic illustrates the traditional and optimized be part of processes in our distributed computing setting.
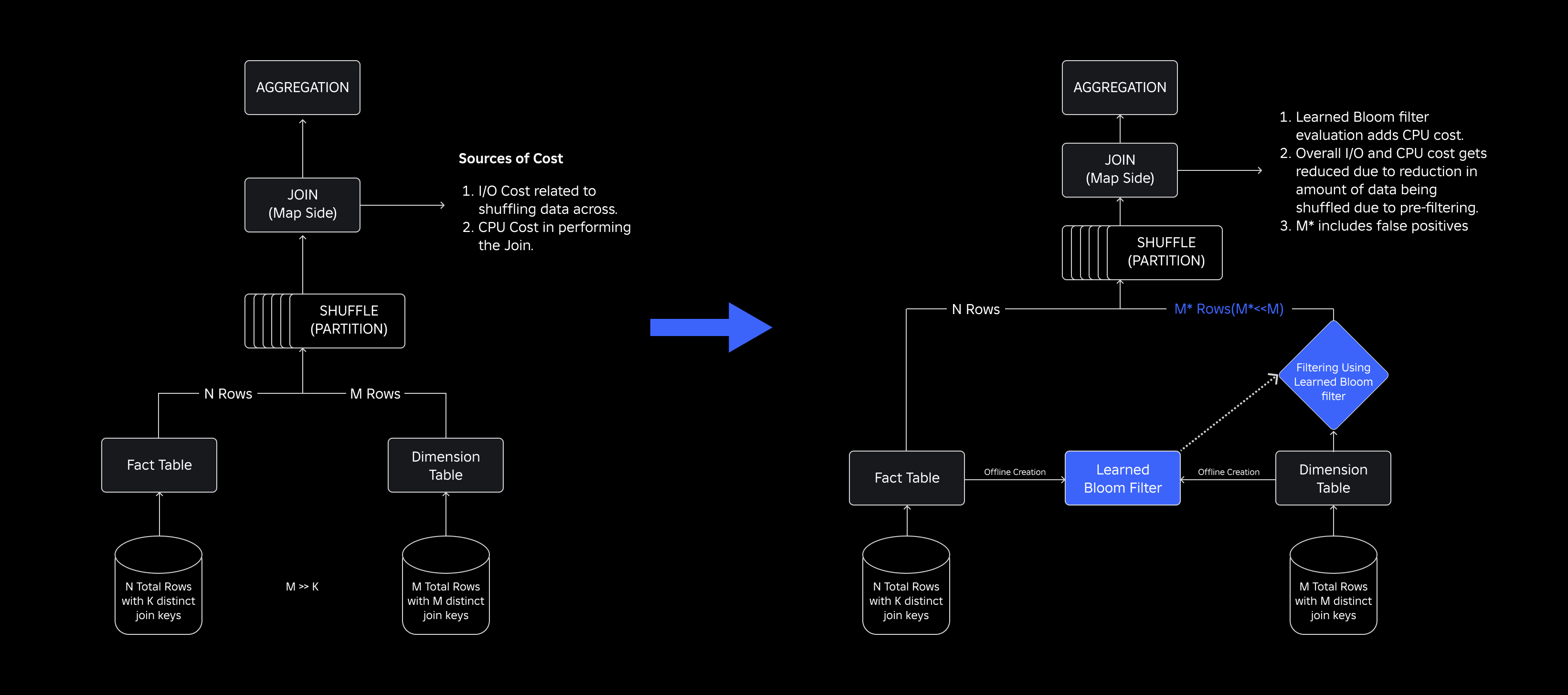
Enhancing Be a part of Effectivity with Discovered Bloom Filters
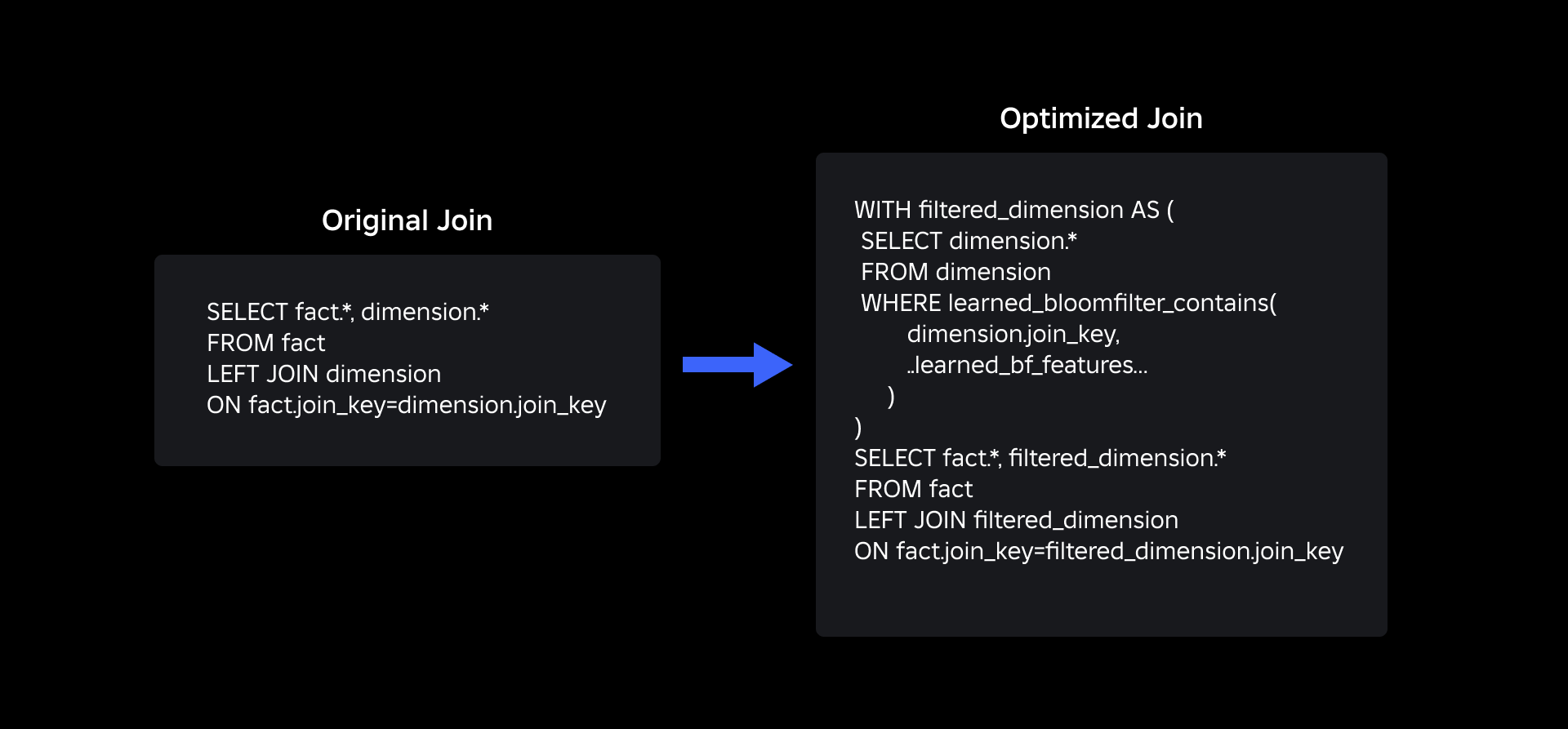
To optimize the be part of between truth and dimension tables, we adopted the Discovered Bloom Filter implementation. We constructed an index from the keys current within the truth desk and subsequently deployed the index to pre-filter dimension knowledge earlier than the be part of operation.
Evolution from Conventional Bloom Filters to Discovered Bloom Filters
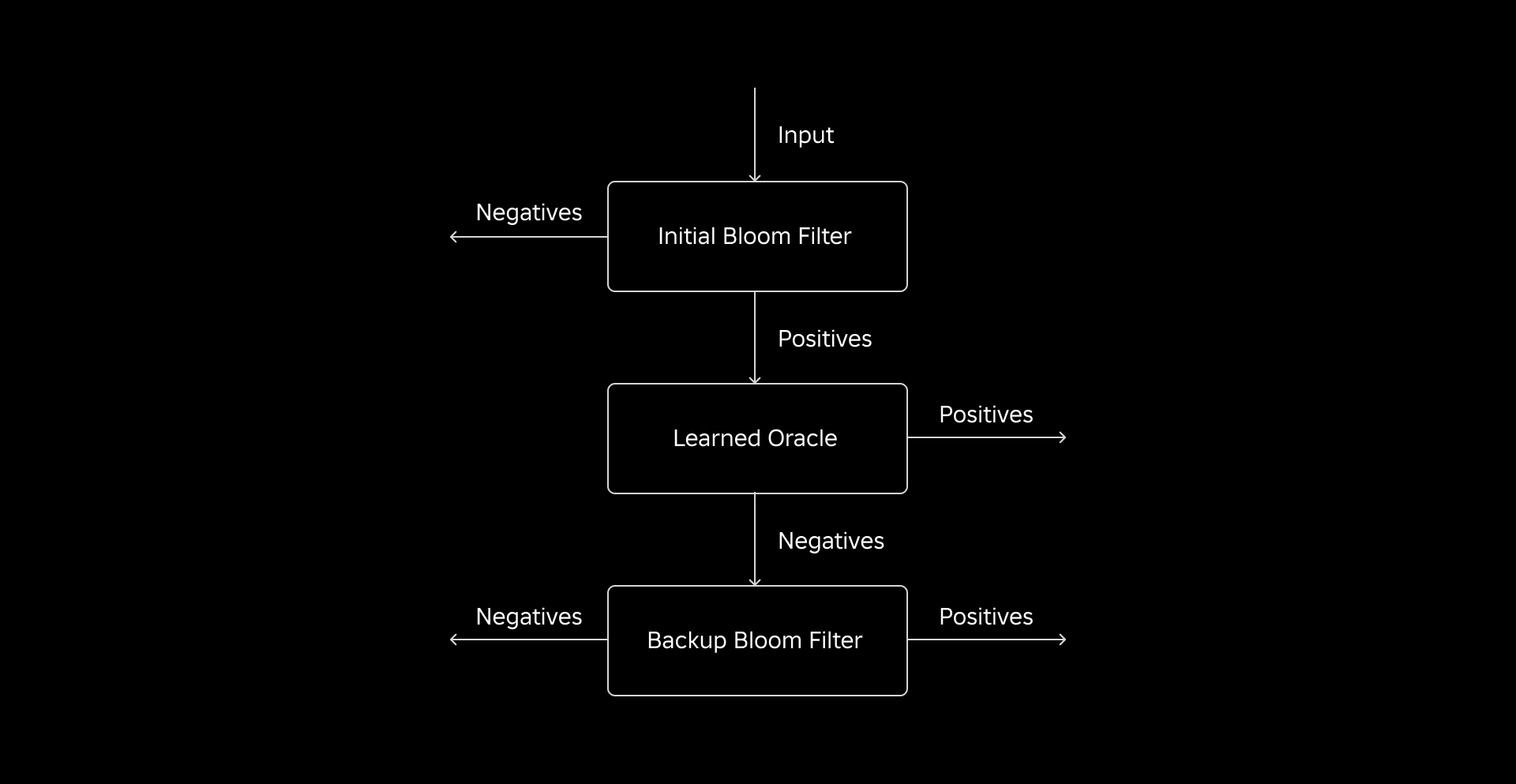
Whereas a standard Bloom Filter is environment friendly, it provides 15-25% of extra reminiscence per employee node needing to load it to hit our desired false constructive charge. However by harnessing Discovered Bloom Filters, we achieved a significantly lowered index measurement whereas sustaining the identical false constructive charge. That is due to the transformation of the Bloom Filter right into a binary classification downside. Constructive labels point out the presence of values within the index, whereas unfavorable labels imply they’re absent.
The introduction of an ML mannequin facilitates the preliminary test for values, adopted by a backup Bloom Filter for eliminating false negatives. The lowered measurement stems from the mannequin’s compressed illustration and lowered variety of keys required by the backup Bloom Filter. This distinguishes it from the traditional Bloom Filter method.
As a part of this work, we established two metrics for evaluating our Discovered Bloom Filter method: the index’s ultimate serialized object measurement and CPU consumption in the course of the execution of be part of queries.
Navigating Implementation Challenges
Our preliminary problem was addressing a extremely biased coaching dataset with few dimension desk keys within the truth desk. In doing so, we noticed an overlap of roughly one-in-three keys between the tables. To sort out this, we leveraged the Sandwich Discovered Bloom Filter method [2]. This integrates an preliminary conventional Bloom Filter to rebalance the dataset distribution by eradicating the vast majority of keys that have been lacking from the very fact desk, successfully eliminating unfavorable samples from the dataset. Subsequently, solely the keys included within the preliminary Bloom Filter, together with the false positives, have been forwarded to the ML mannequin, sometimes called the “realized oracle.” This method resulted in a well-balanced coaching dataset for the realized oracle, overcoming the bias situation successfully.
The second problem centered on mannequin structure and coaching options. In contrast to the traditional downside of phishing URLs [1], our be part of keys (which typically are distinctive identifiers for customers/experiences) weren’t inherently informative. This led us to discover dimension attributes as potential mannequin options that may assist predict if a dimension entity is current within the truth desk. For instance, think about a truth desk that incorporates person session info for experiences in a specific language. The geographic location or the language choice attribute of the person dimension can be good indicators of whether or not a person person is current within the truth desk or not.
The third problem—inference latency—required fashions that each minimized false negatives and supplied speedy responses. A gradient-boosted tree mannequin was the optimum selection for these key metrics, and we pruned its characteristic set to stability precision and velocity.
Our up to date be part of question utilizing realized Bloom Filters is as proven beneath:
Outcomes
Listed below are the outcomes of our experiments with Discovered Bloom filters in our knowledge lake. We built-in them into 5 manufacturing workloads, every of which possessed completely different knowledge traits. Probably the most computationally costly a part of these workloads is the be part of between a truth desk and a dimension desk. The important thing house of the very fact tables is roughly 30% of the dimension desk. To start with, we focus on how the Discovered Bloom Filter outperformed conventional Bloom Filters by way of ultimate serialized object measurement. Subsequent, we present efficiency enhancements that we noticed by integrating Discovered Bloom Filters into our workload processing pipelines.
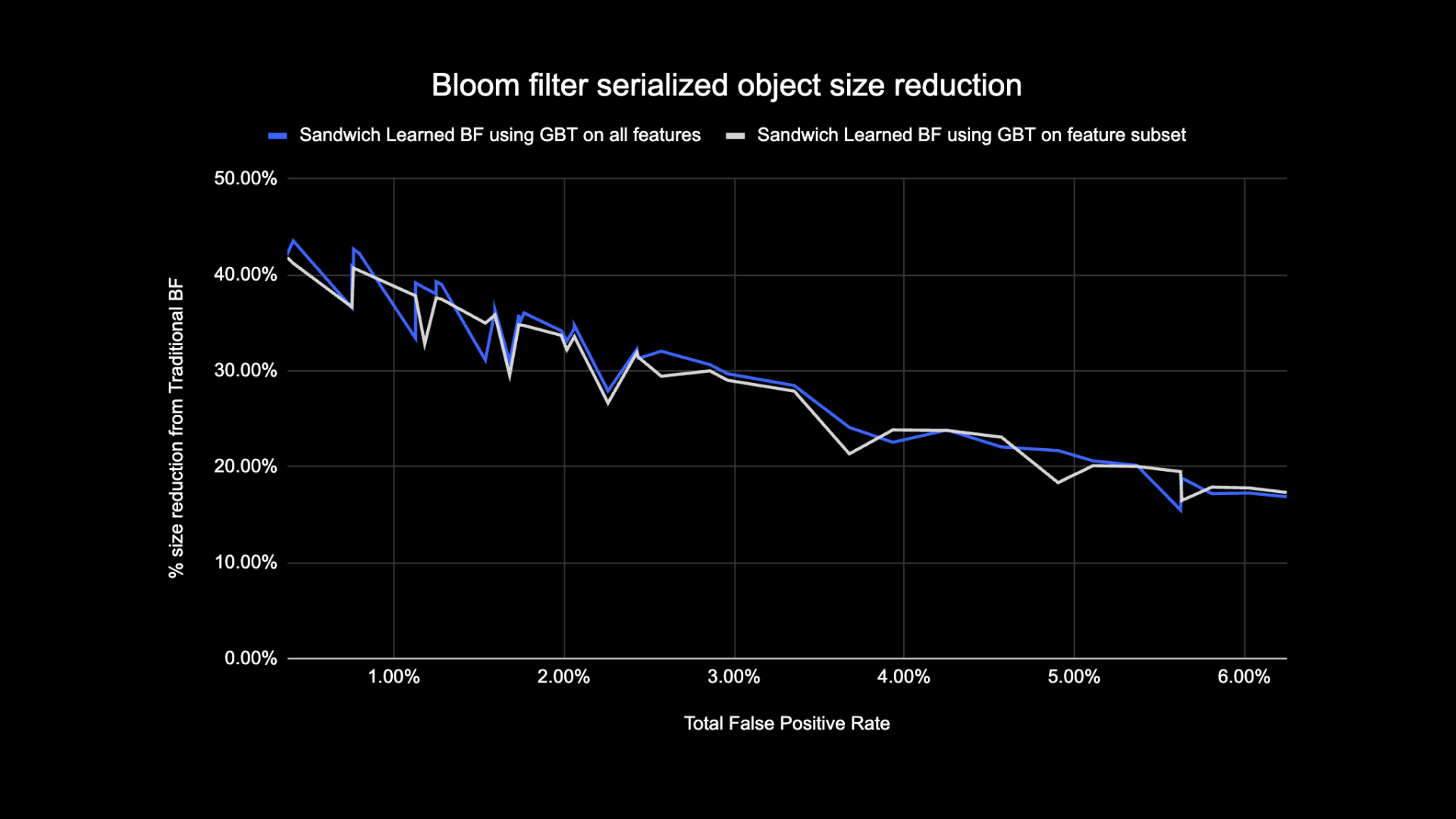
Discovered Bloom Filter Dimension Comparability
As proven beneath, when taking a look at a given false constructive charge, the 2 variants of the realized Bloom Filter enhance complete object measurement by between 17-42% when in comparison with conventional Bloom Filters.
As well as, through the use of a smaller subset of options in our gradient boosted tree primarily based mannequin, we misplaced solely a small share of optimization whereas making inference sooner.
Discovered Bloom Filter Utilization Outcomes
On this part, we examine the efficiency of Bloom Filter-based joins to that of standard joins throughout a number of metrics.
The desk beneath compares the efficiency of workloads with and with out using Discovered Bloom Filters. A Discovered Bloom Filter with 1% complete false constructive chance demonstrates the comparability beneath whereas sustaining the identical cluster configuration for each be part of varieties.

First, we discovered that Bloom Filter implementation outperformed the common be part of by as a lot as 60% in CPU hours. We noticed a rise in CPU utilization of the scan step for the Discovered Bloom Filter method as a result of extra compute spent in evaluating the Bloom Filter. Nevertheless, the prefiltering performed on this step lowered the scale of knowledge being shuffled, which helped cut back the CPU utilized by the downstream steps, thus lowering the whole CPU hours.
Second, Discovered Bloom Filters have about 80% much less complete knowledge measurement and about 80% much less complete shuffle bytes written than a daily be part of. This results in extra secure be part of efficiency as mentioned beneath.
We additionally noticed lowered useful resource utilization in our different manufacturing workloads beneath experimentation. Over a interval of two weeks throughout all 5 workloads, the Discovered Bloom Filter method generated a mean day by day price financial savings of 25%, which additionally accounts for mannequin coaching and index creation.
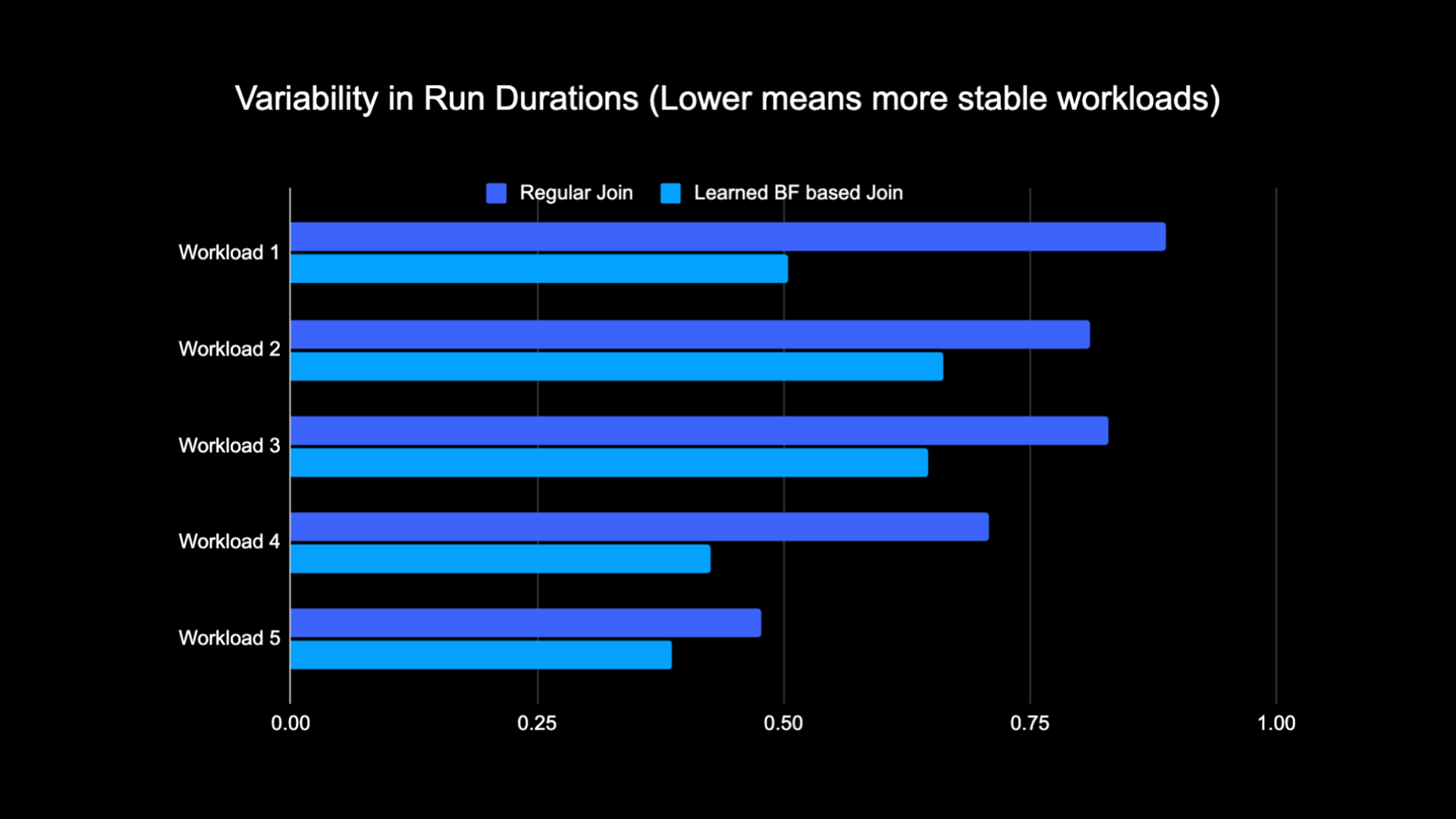
Because of the lowered quantity of knowledge shuffled whereas performing the be part of, we have been in a position to considerably cut back the operational prices of our analytics pipeline whereas additionally making it extra secure.The next chart exhibits variability (utilizing a coefficient of variation) in run durations (wall clock time) for a daily be part of workload and a Discovered Bloom Filter primarily based workload over a two-week interval for the 5 workloads we experimented with. The runs utilizing Discovered Bloom Filters have been extra secure—extra constant in length—which opens up the potential for shifting them to cheaper transient unreliable compute sources.
References
[1] T. Kraska, A. Beutel, E. H. Chi, J. Dean, and N. Polyzotis. The Case for Discovered Index Buildings. https://arxiv.org/abs/1712.01208, 2017.
[2] M. Mitzenmacher. Optimizing Discovered Bloom Filters by Sandwiching.
https://arxiv.org/abs/1803.01474, 2018.
¹As of three months ended June 30, 2023
²As of three months ended June 30, 2023
[ad_2]
Source link


{kind=link}